
Inhaltsverzeichnis
Nachdem wir in Teil 1 noch einmal durchlebt haben, wie mein erster Schritt in Richtung papierloses Büro kläglich an der Suchfunktion meiner NAS scheiterte, wird es heute etwas technischer. Nicht zu technisch, aber so, dass man versteht, warum Paperless-NGX kein weiteres Ablagesystem ist, sondern ein tatsächliches Dokumentenmanagement-System. Paperless-NGX denkt zudem über die Möglichkeiten eines effektiven digitalen Büros nach.
Denn seien wir ehrlich: Scannen allein war schnell erledigt. Das Wiederfinden hingegen war das eigentliche Problem. Und genau da beginnt Paperless-NGX zu glänzen.
Ein kurzer Rückblick
Ich hatte bereitwillig meine Versicherungsunterlagen, Verträge und vieles mehr digitalisiert. Alles lag auf der NAS. Theoretisch fein. Praktisch nutzlos. Denn ohne Suchfunktion und ohne Metadaten wird ein PDF auf der NAS eben nicht besser als ein Blatt Papier im Ordner.
Das war der Punkt, an dem ich mir dachte: Es braucht ein System, das mehr kann, als Dateien abzuspeichern. Es braucht Struktur. Und damit kommen wir zu Paperless-NGX.
Was Paperless-NGX eigentlich macht
Paperless-NGX ist im Kern ein Verwaltungs-, Sortier- und Analysewerkzeug für Dokumente. Es übernimmt drei Aufgabenbereiche, die in klassischen Dateisystemen schlicht fehlen.
1. Dokumente importieren
Paperless-NGX nimmt Dokumente über verschiedene Wege entgegen:
- Über einen überwachten Consume-Ordner
- Über manuelles Hochladen
- Über E-Mail-Import (Teil 6 der Serie)
- Über mobile Apps (optional)
- Über Automatisierungen und Scripts
Der wichtige Punkt: Der Import ist nur der Anfang. Noch ist das Dokument unklassifiziert – sozusagen frisch im Briefkasten.
2. Dokumente analysieren
Sobald ein Dokument importiert wurde, legt Paperless-NGX los:
- Das PDF wird geprüft: Handelt es sich um Text oder ein reines Bild?
- Falls nötig: OCR (Texterkennung). Damit wird der Inhalt durchsuchbar.
- Der erkannte Text wird indexiert und in der Datenbank abgelegt.
- Automatische Vorschläge können entstehen (Dokumententyp, Korrespondent, Datum).
- Duplikate werden erkannt.
Damit wird aus einem Bild ein recherchierbares Dokument.
3. Dokumente organisieren
Hier beginnt der eigentliche Vorteil:
- Dokumententypen definieren, was für ein Dokument vorliegt
(Rechnung, Vertrag, Versicherung, Schreiben, Quittung …) - Tags helfen, Informationen zu bündeln
(Haus, Auto, Versicherung, Steuern, Rechnungen, Garantien) - Korrespondenten beschreiben den Absender
(Versicherungsgesellschaft, Energieversorger, Händler) - Datum, Betreff, Nummern – alles wird zentral gespeichert
Und das Entscheidende:
Ein Dokument kann zu mehreren Tags gehören, ohne doppelt irgendwo liegen zu müssen.
Der empfohlene Workflow visualisiert
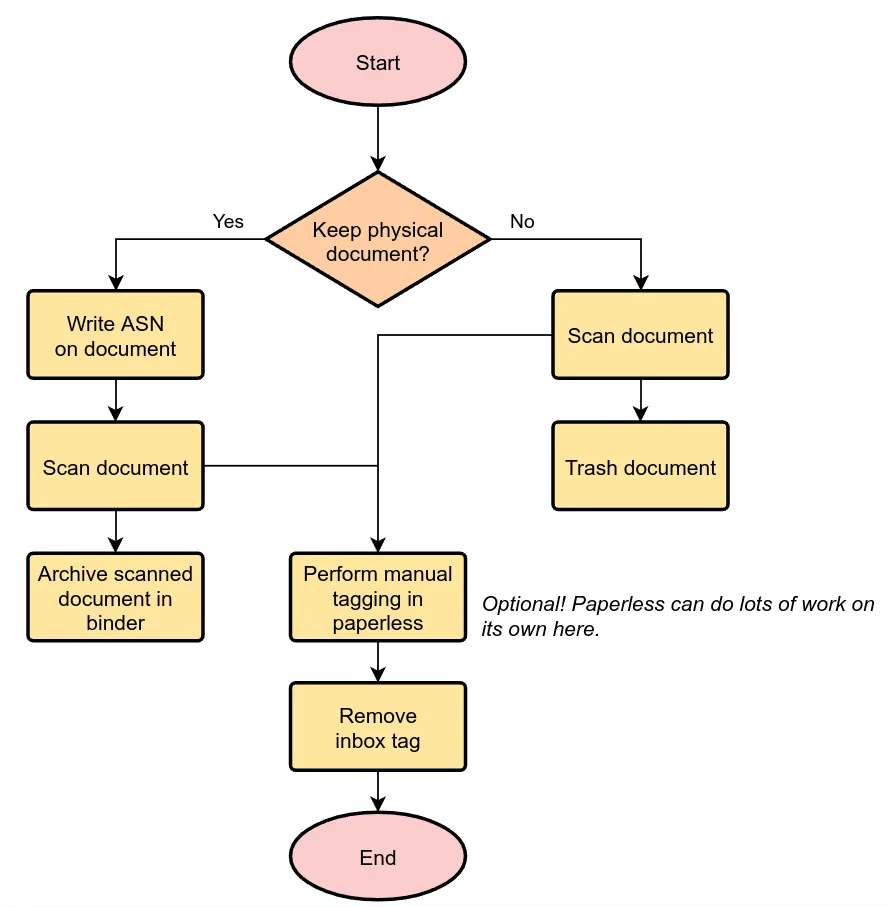
- Dokument kommt rein
- Entscheidung: Original behalten oder nicht
- Scannen bzw. digital übernehmen
- In Paperless-NGX importieren
- Metadaten vergeben (manuell oder automatisch)
- „Inbox“-Markierung entfernen, wenn alles korrekt ist
- Dokument ist archiviert und über die Suche auffindbar
Dieser Ablauf ist der Kern des Systems. Kein „Wirf die Datei einfach mal in Ordner XY“, sondern ein definierter Prozess.
Was passiert technisch beim Import?
Damit es einmal greifbar wird, hier ein vereinfachter Blick hinter die Kulissen:
- Die Datei landet im Consume-Ordner.
- Paperless-NGX überprüft, ob sie bereits existiert (Duplikaterkennung).
- Das Dokument wird umgewandelt, falls nötig (z. B. PDF/A).
- Die OCR-Engine (Tesseract) liest den Text aus.
- Der Text wird im Suchindex abgelegt.
- Alle Dokumentdaten (Datum, Dateiname, OCR-Text) landen in der Datenbank.
- Das Dokument erhält automatisch das Tag „inbox“.
- Nun ist das Dokument bereit für die finale Einordnung.
Für dich heißt das:
Kein manuelles Umbenennen mehr, keine Ordnerstruktur überlegen, kein Sortieren in 20 Kategorien.
Paperless-NGX übernimmt den Großteil – du schließt nur noch ab.
Warum Paperless-NGX sofort mehr Ordnung schafft als eine NAS
Hier der Kernunterschied:
| NAS-Ablage | Paperless-NGX |
|---|---|
| Ablageort | Ablagesystem |
| Dateiname wichtig | Metadaten wichtig |
| Suche nur nach Dateiname | Volltextsuche |
| Keine Vorschläge | Automatische Vorschläge |
| Keine Kategorisierung | Tags, Typen, Korrespondenten |
| Ein Dokument = ein Ordner | Ein Dokument = beliebig viele Kategorien |
| Keine Historie | Änderungsverlauf & Index |
Das zeigt schon: Mit Paperless-NGX wird aus einem PDF ein „Dokument“, nicht mehr nur eine Datei.
Vorbereitung auf Teil 3
Im nächsten Teil steigen wir in die technische Umsetzung ein:
- Wo läuft Paperless-NGX am besten?
NAS, Docker oder Linux-Server? - Was braucht man vorher?
- Welche Ordnerstruktur sollte man anlegen?
- Wie startet man das System zum ersten Mal?
Teil 3 wird ein klassischer Setup-Artikel, leicht verständlich, aber technisch fundiert.
Weiterführende Artikel dieser Serie
- Teil 1: Warum Scannen allein nicht reicht
- Teil 2: Wie Paperless-NGX im Hintergrund arbeitet – Dieser Artikel
- Teil 3: Installation & Setup auf meiner UGREEN-NAS
- Teil 4: Konfiguration & Strukturen
- Teil 5: Papier-Workflow
- Teil 6: E-Mail-Import
- Teil 7: Automatisierung & Workflows
- Teil 8: Backups & Sicherheit
- Teil 9: Praxisbeispiele
- Teil 10: Mein komplettes Setup
- Mein optimiertes docker-compose.yml für Paperless-NGX auf der UGREEN-NAS
- Automatisierungsregeln & Templates – Paperless-NGX Serie
- Paperless GPT – Die perfekte Ergänzung zu Paperless-NGX
- Wartung der Paperless Instanz auf dem UGREEN NAS
8 Gedanken zu „Wie Paperless-NGX denkt – Paperless-ngx – Teil 2“